 |
Prime I.T. | |
|
Soutenir Prime I.T. : |
 English version
English version
|
 Adresse pour les Bitcoins
Adresse pour les Bitcoins  Adresse pour les Litecoins
Adresse pour les Litecoins  Adresse pour les Dodgecoins
Adresse pour les Dodgecoins La division euclidienne
Le principe
Cet article traite de la division euclidienne, sujet fondamental, représentant le point
de départ de toutes les problématiques liées aux nombres premiers et à la factorisation
des entiers.
La division euclidienne est avec l'addition, la soustraction et la multiplication l'une
des quatre opérations élémentaires sur les nombres entiers. Elle a pour but d'essayer de
repartir équitablement un groupe déléments donnés par rapport à une contrainte
caractérisée par un nombre.
Par exemple un sac contenant 12 billes à répartir sur 3 personnes ou alors le gâteau de
grand' maman coupé en 8 parts alors que nous sommes 6 à table.
Nous considérons dans cet article que nous travaillons sur les entiers naturels (ensemble
N des entiers positifs), de ce fait cette répartition équitable est quelquefois impossible
sans qu'apparaissent des "demis", des "quarts", des "tiers" ou autres... Par exemple 3
billes à se répartir sur 2 personnes donnent 1 bille chacune et on ne s'amuse pas à couper
la dernière... Ce résidu non réparti est mis de coté, il s'agit du reste.
A noter que sur les rationnels (ensemble Q) et donc sur les réels (très grossièrement les
nombres à virgule) la répartition est possible mais peut donner quelque chose de
difficilement représentable dans la vraie vie, par exemple 10 / 3 = 3.3333... c'est a dire
des 3 à l'infini, difficile de couper un gâteau dans ces conditions...
D'un point de vue mathématique, la définition de la division euclidienne pour les entiers
naturels est la suivante :
Soient a et b deux nombres entiers et avec b différent de 0, il existe un unique couple
(q, r) d'entiers tels que :
- a = bq + r
- r < b
Note 1 : Nous retrouvons bien cette notion de répartition équitable avec le terme "bq" ainsi que le
résidu avec le terme "r".
Note 2 : Pour les entiers relatifs (ensemble Z des nombres entiers positifs et négatifs)
nous avons quasiment la même définition. Seule la deuxième condition change et devient
|r| < |b|.
Concernant la dénomination des termes de la division euclidienne "a = bq + r", nous avons :
- a est le dividende
- b est le diviseur
- q est le quotient
- r est le reste
Mise en place des tests
Tout au long de cet article nous allons présenter quelques implémentations connues de la division euclidienne et les comparer entre elles afin de voir lesquelles sont les plus efficaces et les plus rapides. Mais pour pouvoir évaluer ces temps et confronter les résultats, il nous faut un petit programme de test qui devra mesurer les temps des différentes implémentations de la division et aussi répondre aux 3 critères suivants afin d'éviter les biais dans les tests :
- Les jeux de test doivent être conséquent : une division étant de l'ordre de la milliseconde, si nous testons juste une division nous ne pourrons pas en extraire des informations pertinentes car les temps sont trop courts. Nous allons donc faire des tirs sur 20 millions de divisions.
- Les jeux de test doivent être identique pour chaque implémentation : pour pouvoir comparer 2 implémentations de la division euclidienne, il faudra être sûr d'utiliser le même jeu de test car diviser avec des méthodes différentes sur des nombres différents n'a aucun intérêt.
- Faire plusieurs jeux de test avec des propriétés différentes : l'idée est de pouvoir tester les implémentations de la division sur des jeux ayant des propriétés différentes afin de mettre en avant les points forts et les points faibles de l'implémentation.
La classe java EuclideTestCaseGenerator est en charge de la génération de ces jeux de test.
Celle-ci va créer les jeux selon 3 méthodes : l'une dit "aléatoire" qui va prendre aléatoirement
les nombres a (le dividende) et b (le diviseur) entre 1 et 1000 milliards, une autre dit "A > B"
idem à "aléatoire" sauf que a est obligatoirement supérieur à b et une dernière "custom"
identique à aléatoire avec a > 4*b.
Enfin, la classe java EuclideBench est l'orchestrateur permettant de lancer les implémentations
de la division euclidienne. Les implémentations devront implémenter (au sens java) l'interface
IEuclide.
source
Première implémentation
Le plus simple pour calculer la division euclidienne est de se reposer sur sa définition : "combien de fois je peux mettre b dans a ?". Cela se traduit par un algorithme facile à faire et relativement court consistant à soustraire autant de fois que l'on peut b (le diviseur) de a (le dividende), jusquà obtenir un reste inférieur à b.
long r = a;
long q = 0;
while (r >= b) {
r = r - b;
q = q + 1;
}
long[] euclide = { q, r };
return euclide;
}
Pour l'instant nous n'avons pas encore déléments de comparaison avec les autres
implémentations mais croyez-moi la méthode est naïve :).
Tout ce que nous pouvons remarquer sur cet algorithme est son risque à ne pas aboutir
lorsque a est trop grand devant b car le variable r dans l'instruction "r = r - b"
ne décroît pas assez rapidement. La complexité de l'algorithme est en O(a).
source
Deuxieme implementation
Afin d'améliorer la première implémentation, il pourrait être intéressant de coder
la division décimale que nous apprenons à l'école. Et pour ceux qui ne se souviennent plus
de comment ça marche, nous mettons ci-dessous un simple schéma qui vaut bien mieux qu'un
long discours pour se remémorer de la méthode... enfin attention le schéma montre comment
apprennent les petits français. Selon le coin du monde où vous avez étudié la position
des nombres et le visuel change mais globalement les principes restent les mêmes :
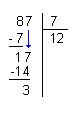 C'est à dire 87 = 7 * 12 + 3
C'est à dire 87 = 7 * 12 + 3
Au niveau de l'implémentation, la méthode consiste donc à multiplier b (le diviseur) par
10 plusieurs fois tant qu'il est inférieur à a (le dividende) puis de faire la division
à l'identique de la première implémentation et enfin de recommencer avec comme dividende
le reste de la division de l'étape précédente.
long r = a;
long q = 0;
long n = 1;
long aux = 0;
while (r >= b) {
while (b * n <= a) {
n *= 10;
}
n /= 10;
aux = b * n;
while (r >= aux) {
r = r - aux;
q = q + n;
}
a = r;
n = 1;
}
long[] euclide = { q, r };
return euclide;
}
Tout au long de cet article nous allons donner les résultats sous la forme de 3 tables
représentant un tir sur chacun des 3 jeux de test (Aléatoire, A > B et A > 4 * B).
Il est important de voir que le sens de lecture est de haut en bas et qu'il faut comparer
les algorithmes uniquement dans le cadre d'un tir. Ici nous avons pris aléatoirement 40
millions de nombres (2 fois 20 millions) et calculé le temps pris par l'algorithme naïf
et décimal pour faire 20 millions de divisions euclidiennes (il s'agit du tir 1). Puis
nous avons pris d'autres nombres telque A > B et refait les 20 millions de divisions
(tir 2) puis pareil pour A > 4 * B (tir 3).
Tout ça pour dire qu'il y a peu d'intérêt à comparer 2 tirs distincts puisque les jeux
de données sont différents même s'il est vrai que nous voyons que le temps augmente entre
les 3 jeux, cette croissance est difficilement quantifiable.
Voyons un peu ce que cela donne.
| Aléatoire | A > B | A > 4 * B | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Tir / Check | n°1 / 150660990 | n°2 / 294686702 | n°3 / 1221575580 | ||||||
| Naive | 1.437 | 2.281 | 5.375 | ||||||
| Décimale | 2.0 | +0.563 | 2.984 | +0.703 | 4.032 | -1.343 | |||
Cette deuxième implémentation nous montre que la méthode naïve est plus rapide
lorsque nous prenons des valeurs au hasard ou lorsque a (le dividende) est plus
grand que b (le diviseur) car l'algorithme est simplissime et va vite. Par contre dès
que b est 4 fois plus petit que a, les performances s'inversent et la méthode décimale
devient beaucoup plus rapide.
Concernant le cas de test A > B on peut se demander pourquoi il n'y a pas de gain ?
Tout simplement parce que le jeu de test est inadapté ! Le problème vient de la
répartition des nombres lors d'un tir aléatoire. Par exemple si nous choisissons un
nombre entre 0 et 1000 nous avons 89,99% de chance de tomber sur un nombre de 4 chiffres
(résultat extrapolable à n chiffres), sur ces nombres à 4 chiffres nous avons des ratios
a / b très faible et donc le résultat A > B est peu probant. En rajoutant la
condition A > 4 * B nous augmentons artificiellement le ratio et nous voyons un gain
net.
Ce deuxième algorithme est donc moins dépendant du ratio a / b car nous commençons par
multiplier b par 10 autant de fois qu'il le faut pour être au plus près de a.
source
Troisième implementation
Afin d'optimiser les temps de calcul de la division euclidienne, nous allons changer de
stratégie en implémentant un algorithme basé sur la dichotomie. Cette méthode permet de faire
une recherche extrêmement rapide sur une valeur en utilisant le bon vieil adage "diviser
pour mieux régner".
Ici la recherche dichotomique va se focaliser sur la valeur de q (le quotient). L'approche
consiste dans un premier temps à borner q, puis de façon répétitive à couper en deux parties
égales cet intervalle et à sélectionner l'intervalle qui contient q.
Il est à noter que ces opérations de bornage et de découpage vont se faire avec des puissances
de 2 ou en d'autres termes, nous allons utiliser du binaire rendant ainsi les opérations plus
faciles pour un ordinateur.
Pour trouver la première borne de q, nous commençons par rechercher un n tel que
b * 2^n-1 <= a < b * 2^n, que nous pouvons traduire en 2^n-1<= q <2^n.
Ensuite nous lançons la recherche dichotomique en posant auparavant
alpha = 2^n-1 et beta = 2^n
Les critères de la dichotomie sont les suivant :
- Si b * ((alpha + beta) / 2) <= a alors alpha = (alpha + beta) / 2
- Si b * ((alpha + beta) / 2) > a alors beta = (alpha + beta) / 2
Et ça marche ! Petit a petit nous nous rapprochons (et nous trouvons) le quotient q. Pour plus
de détails, notamment sur la démonstration mathématique de la méthode, se référer à l'article
Wikipédia sur la division
euclidienne (section methode binaire).
long n = 0;
long aux = b;
if (a < b) {
long[] euclide = { 0, a };
return euclide;
}
while (aux <= a) {
aux = (aux << 1);
n++;
}
long alpha = (1 << (n - 1));
long beta = (1 << n);
while (n-- > 0) {
aux = (alpha + beta) >> 1;
if ((aux * b) <= a) {
alpha = aux;
} else {
beta = aux;
}
}
long[] euclide = { alpha, a - (b * alpha) };
return euclide;
}
Et nous améliorons les performances...
Avec une approche par dichotomie nous sentons qu'un "gap" a été franchi. Autant la méthode
décimale permet un gain important sous condition que a (le dividende) soit très grand
devant b (le diviseur), autant ici nous avons l'impression d'un gain généralisé sur tous les
jeux de test. Et c'est normal puisque nous sommes passé en log2(a).
source
| Aléatoire | A > B | A > 4 * B | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Tir / Check | n°4 / 198332981 | n°5 / 394652967 | n°6 / 1390554002 | ||||||
| Naive | 1.578 | 2.75 | 5.921 | ||||||
| Décimale | 2.0 | +0.422 | 3.0 | +0.25 | 4.032 | -1.889 | |||
| Dichotomie binaire | 1.375 | -0.625 | 2.015 | -0.985 | 3.297 | -0.735 | |||
Quatrième implementation
Toujours en quête de performance, nous faire un grand bond en arrière dans l'histoire des
civilisations puisque nous allons nous inspirer de la technique de la division dans l'Egypte antique
pour implémenter le quatrième algorithme de la division euclidienne.
Question : les Egyptiens à l'époque des pharaons étaient ils tous des informaticiens en puissance ?
Nul ne le sait mais leurs techniques de multiplication
et de division
s'appuyaient essentiellement sur la décomposition des nombres en puissance de 2 pour pouvoir faire ces 2
opérations. En gros ils raisonnaient en binaire pour pouvoir multiplier et diviser.
- Concernant la multiplication, le but était de transformer en binaire le premier opérateur
(voir Wikipédia pour cette transformation) puis de construire la table des puissances de 2
multiplié par le second opérateur (facile, il suffit de multiplier par 2 le 2eme opérateur
autant de fois que l'on souhaite), enfin d'additionner les valeurs de la table là "où il y a
un 1 binaire".
Exemple avec 18 * 9 = ? 18 (binaire) 9 * 2 (n fois) 0 9 1 18 il y a 1, on prend 0 36 0 72 1 144 il y a 1, on prend Donc 18 + 144 = 162 = 18 * 9.
- Concernant la division, les Egyptiens utilisaient le même principe mais en sens inverse.
Ils commençaient par construire la table des puissances de 2 multiplié par le diviseur (toujours grâce à une multiplication par 2) jusqu'à arriver à un nombre supérieur à a (le dividende). Ensuite ils reconstruisaient "le résultat en binaire" en sélectionnant les nombres tels que leurs additions ne dépassent pas a. Cette sélection commençait à partir du nombre le plus grand (le bit le plus fort).
Exemple avec 218 / 6 = ? n 6 * 2 (n fois) Addition 5 192 192 on prend car 192 < 218 4 96 X on ne prend pas car 192 + 96 = 288 et 288 > 218 3 48 X on ne prend pas car 192 + 48 > 218 2 24 216 on prend car 192 + 24 = 216 et 216 < 218 1 12 X on ne prend pas car 216 + 12 > 218 0 6 X on ne prend pas car 216 + 6 > 218 Donc 192 + 24 = 216, c'est a dire 6 * (2 ^ 5) + 6 * (2 ^ 2) = 216.
Le quotient q est 2 ^ 5 + 2 ^ 2 = 36 et le reste r est 2 (218 - 116).
La majorité des sites sur la toile traitent de la division égyptienne selon une approche historique et non informatique. Nous trouvons donc le principe de fonctionnement et bon nombre d'informations relatant du sujet sous une forme textuelle. Par contre nous n'avons pas vu d'exemple d'implémentation de l'algorithme, mais qu'à cela ne tienne, à nous de le faire !
long n = 0;
long p = b;
if (a < b) {
long[] euclide = { 0, a };
return euclide;
}
while (p <= a) {
p = (p << 1);
n++;
}
p = (p >> 1);
n--;
long q = (1 << n);
long aux = p;
while (n > 0) {
p = (p >> 1);
n--;
if ((aux + p) <= a) {
q += (1 << n);
aux += p;
}
}
long[] euclide = { q, a - aux };
return euclide;
}
Au niveau des variables, nous avons :
- p : représentant les calculs sur b * 2 ^ n (la 2ème colonne dans l'exemple) sur laquelle nous faisons nos multiplications et divisions par 2 via un "shift".
- aux : représentant l'addition ne devant pas dépasser le dividende (3ème colonne dans l'exemple).
Nous remarquons que l'algorithme ressemble beaucoup à la division binaire par dichotomie, notamment
la première partie ou nous devons rechercher n pour pouvoir borner a (le dividende) tel que
b * 2^n-1 <= a < b * 2^n mais aussi la boucle "while (n > 0)" au centre du programme.
En fait ces 2 algorithmes sont équivalents, l'un pouvant être écrit en l'autre.
source
Au niveau des performances, nous gagnons encore en vitesse. Certes pas autant que le passage
décimale vers dichotomique mais le gain de 0.2s en moyenne (hors aléatoire) est honorable.
| Aléatoire | A > B | A > 4 * B | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Tir / Check | n°7 / 162438146 | n°8 / 313167294 | n°9 / 1211389641 | ||||||
| Naive | 1.406 | 2.781 | 5.5 | ||||||
| Décimale | 2.016 | +0.61 | 3.0 | +0.219 | 3.828 | -1.672 | |||
| Dichotomie binaire | 1.39 | -0.626 | 2.0 | -1.0 | 3.015 | -0.813 | |||
| Egyptienne binaire | 1.36 | -0.03 | 1.781 | -0.219 | 2.719 | -0.296 | |||
Cinquième implementation
Et voici la dernière implémentation de la division euclidienne, il s'agit de la méthode
de dichotomie binaire complétée avec Horner.
Dans les faits il s'agit tout simplement d'une réécriture plus élégante de la division
égyptienne (quatrième implémentation) qui elle même est équivalente à la troisième
(si vous suivez...).
long r = a;
long q = 0;
long n = 0;
long aux = b;
while (aux <= a) {
aux = (aux << 1);
n++;
}
while (n > 0) {
aux = (aux >> 1);
n--;
q = (q << 1);
if (r >= aux) {
r = r - aux;
q++;
}
}
long[] euclide = { q, r };
return euclide;
}
Au niveau des performances c'est moins bon sur notre vieil AMD 3200 2 Ghz de test que
l'implémentation de la division égyptienne, à voir si sur d'autres machines (et d'autres
languages) nous avons également cette différence.
source
| Aléatoire | A > B | A > 4 * B | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Tir / Check | n°10 / 394782450 | n°11 / 411583635 | n°12 / 1593795009 | ||||||
| Naive | 2.828 | 2.859 | 6.562 | ||||||
| Décimale | 3.031 | +0.203 | 3.078 | +0.219 | 4.031 | -2.531 | |||
| Dichotomie binaire | 2.125 | -0.906 | 2.078 | -1.0 | 3.313 | -0.718 | |||
| Egyptienne binaire | 1.829 | -0.296 | 1.844 | -0.234 | 3.015 | -0.298 | |||
| Binaire | 2.046 | +0.217 | 2.031 | +0.187 | 3.172 | +0.157 | |||
En conclusion
Et voilà, ainsi se termine la présentation de quelques algorithmes de la division
euclidienne. On remarquera que nous avons vu 5 implémentations, ce qui est un nombre
élevé mais il est fort probable qu'il en existe bien d'autres non commenté et/ou non
visible.
